1,512
Scenes
Reference-conditioned Oddity and Symbolic Execution

Can a multimodal model turn the same visual evidence into the exact action required by the current task context?
Global counting, local counting, local clicking, visual-region clicking, and exclusion actions are derived from the same underlying scene.
Outputs are automatically evaluated as COUNT, coordinate-level CLICK, or click-count SUBMIT actions.
Global-click and matched local count-to-click controls separate output validity, coordinate grounding, and context-conditioned action.
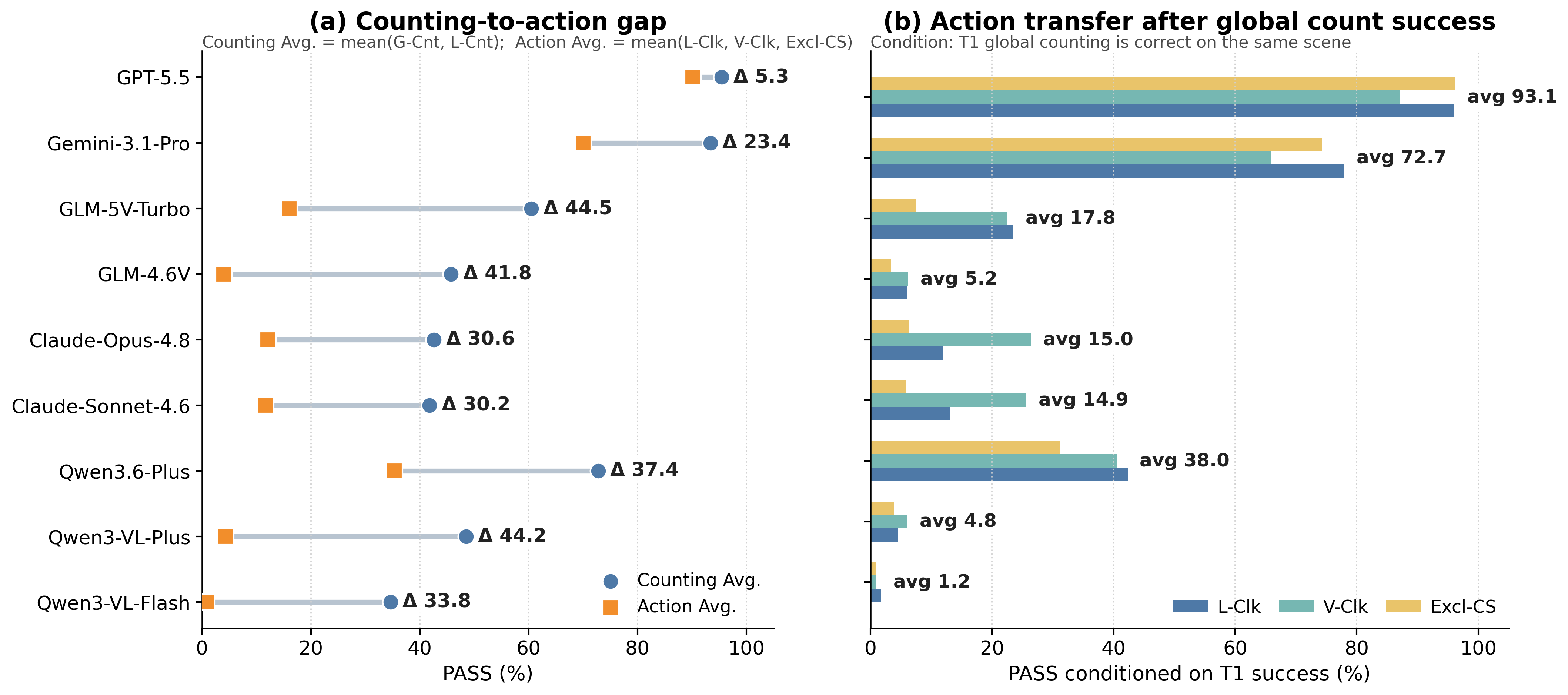
Multimodal large language models (MLLMs) are increasingly expected to act on visual information, yet the same scene may require different actions under different task contexts. How reliably can a model turn the same visual evidence into the action required by the current context? To answer this question, we introduce ROSE (Reference-conditioned Oddity and Symbolic Execution), a controlled benchmark that holds the visual scene fixed while varying region constraints and required symbolic outputs. Through coupled counting and coordinate-action tasks, ROSE tests whether models can infer an implicit majority reference and act on the resulting fine-grained visual evidence under changing contexts. Across nine recent MLLMs, performance drops by as much as 44.5 percentage points from counting-oriented tasks to region-conditioned action, despite 98.8% human performance. The gap persists on paired scenes and regions for which the same model returns the correct count, while global-click and matched local controls show that coordinate grounding explains only part of the loss, revealing a distinct, model-dependent bottleneck in turning shared visual evidence into context-specific actions.
ROSE is designed as a controlled readout problem: the underlying visual evidence stays fixed, while the relevant region and required symbolic output change. The target identity is never named explicitly; it must be inferred from the scene-internal majority relation.
Distinct but visually confusable Chinese characters rendered with the same verified font.
The same emoji identity shown with different provider-specific rendering styles.
Visually related emoji identities rendered in a shared style.
A localized modification introduced into the same pixel-art source asset.
Related but distinct pixel-art assets with matched visual structure or theme.
| Template | Task | Region / context | Required output |
|---|---|---|---|
T1 |
Global counting | Whole grid | COUNT(n) |
T2 |
Local counting | Numeric row, column, or rectangle | COUNT(n) |
T3 |
Local clicking | Numeric row, column, or rectangle | CLICK(...); DONE |
T4 |
Visual-region clicking | Highlighted region in the image | CLICK(...); DONE |
T5 |
Exclusion clicking with count submission | Outside a specified excluded region | CLICK(...); SUBMIT(n) |
COUNT(n)
CLICK(Rr,Cc); ...; DONE
CLICK(Rr,Cc); ...; SUBMIT(n)
ROSE v0.1 uses an official scene-level split. All task variants and both renderings derived from the same scene are assigned to the same split. Dev and Test below report task-instance counts.
| Subset | Controlled visual source | Scenes | Dev | Test |
|---|---|---|---|---|
| ChineseGlyph | Confusable characters, same verified font | 412 | 555 | 1,505 |
| EmojiStyle | Same emoji, different rendering providers | 300 | 395 | 1,105 |
| EmojiContent | Related emoji identities, shared rendering style | 300 | 395 | 1,105 |
| PixelEdit | Same pixel-art asset, localized edit | 300 | 395 | 1,105 |
| PixelContent | Related but distinct pixel-art assets | 200 | 260 | 740 |
| Total | Five visual sources and five coupled task templates | 1,512 | 2,000 | 5,560 |
ROSE is highly solvable by humans, but current MLLMs exhibit a clear and model-dependent gap between counting-oriented readouts and exact region-conditioned actions.
GPT-5.5 achieves the strongest model result with 92.2% Avg. PASS, followed by Gemini-3.1-Pro with 79.4%. The remaining models range from 14.3% to 50.3%.
The dominant signal is not only model ranking, but the gap from compact counting readouts to context-sensitive coordinate actions. For example, Qwen3.6-Plus reaches 80.3% on global counting but 37.7% on visual-region clicking.
| Model | Avg. PASS | VALID |
|---|---|---|
| Qwen3.6-Plus | 50.3 | 99.9 |
| GLM-5V-Turbo | 33.8 | 99.5 |
| Gemini-3.1-Pro | 79.4 | 93.4 |
| GPT-5.5 | 92.2 | 100.0 |
| Human | 98.8 | — |
| Model | G-Cnt | L-Cnt | L-Clk | V-Clk | Excl-CS | Glyph | Emoji | Pixel | Avg. | VALID |
|---|---|---|---|---|---|---|---|---|---|---|
| Qwen3-VL-Flash | 47.7 | 21.6 | 1.3 | 0.5 | 0.7 | 15.0 | 14.9 | 13.6 | 14.3 | 86.6 |
| Qwen3-VL-Plus | 66.4 | 30.6 | 4.1 | 5.7 | 3.2 | 21.8 | 24.0 | 20.1 | 22.0 | 95.5 |
| Qwen3.6-Plus | 80.3 | 65.3 | 39.5 | 37.7 | 28.9 | 48.4 | 48.0 | 53.6 | 50.3 | 99.9 |
| Claude-Sonnet-4.6 | 62.1 | 21.6 | 9.8 | 20.6 | 4.5 | 28.5 | 25.0 | 20.1 | 23.7 | 61.3 |
| Claude-Opus-4.8 | 64.0 | 21.2 | 9.8 | 21.4 | 4.9 | 30.2 | 25.2 | 20.4 | 24.3 | 62.7 |
| GLM-4.6V | 60.7 | 30.8 | 5.0 | 4.5 | 2.5 | 19.1 | 22.4 | 19.9 | 20.7 | 98.8 |
| GLM-5V-Turbo | 64.2 | 56.9 | 20.6 | 21.4 | 6.1 | 37.5 | 34.5 | 31.3 | 33.8 | 99.5 |
| Gemini-3.1-Pro | 92.8 | 93.9 | 75.4 | 64.2 | 70.4 | 67.6 | 84.5 | 80.1 | 79.4 | 93.4 |
| GPT-5.5 | 93.8 | 97.0 | 93.6 | 84.3 | 92.5 | 87.4 | 94.8 | 92.2 | 92.2 | 100.0 |
| Human | 99.9 | 100.0 | 98.8 | 97.7 | 95.8 | 99.8 | 97.5 | 99.8 | 98.8 | — |
This bridge inserts full-grid coordinate localization between global counting and visual-region clicking.
| Model | G-Cnt | G-Clk | V-Clk |
|---|---|---|---|
| Qwen3.6-Plus | 80.3 | 67.1 | 37.7 |
| Gemini-3.1-Pro | 92.8 | 86.5 | 64.2 |
| GPT-5.5 | 93.8 | 91.8 | 84.3 |
Coordinate grounding explains part of the loss, but the larger degradation often appears only after a region context is introduced.
Each matched pair uses the same image, numeric region, and regional target set; only the output operation changes from COUNT to CLICK.
| Model | mL-Cnt | L-Clk | L-Clk† | Fail† |
|---|---|---|---|---|
| Qwen3.6-Plus | 63.2 | 39.5 | 52.7 | 47.3 |
| GPT-5.5 | 96.7 | 93.6 | 95.8 | 4.2 |
Correct cardinality is highly predictive of exact action for GPT-5.5, but not for Qwen3.6-Plus, especially when the required action is empty.
Even when the independently queried global-count response is correct, the model may fail to rebind the same visual evidence to the current action context.

@misc{wang2026rose,
title={ROSE: Benchmarking the Perception-to-Action Gap in Multimodal Models},
author={Yihao Wang and Zijian He and Jie Ren and Keze Wang},
year={2026},
eprint={2606.19965},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2606.19965}
}